Why use Rust on the backend?
- 1: Your developers already know and like Rust
- 2: Your service interoperates with services that are perf-critical
- 3: Serde
- 4: Databases
- 5: Better modelling of business domain
- 6: Reliability
- Conclusion
I read and liked Andrew Israel's I love building a startup in Rust. I wouldn't pick it again. It makes a lot of sense! He basically says that his startup prioritizes developer productivity over performance. Sensible choice for a start-up founder to make. If Rust is going to slow your developers down, and you don't need its benefits, then you should definitely consider using a different language.
On the other hand, I've been using Rust as high-level language at Cloudflare for a few years now. By "a high-level language" I mean one where performance doesn't really matter much. I've mostly been using it for API servers, where overall latency doesn't really matter too much. I'd be totally fine using a garbage collected language, or an interpreted language, because I don't need to eke out every last microsecond for blazing fast performance. I just want my server to stay up, do its job, and let me ship features quickly.
So why use Rust for a task like that? Well, although Rust has a reputation for being a low-level systems language, it actually does an admirable job of acting like a high-level language. So here's my list of reasons to consider using Rust, even for a project where performance isn't critical.
1: Your developers already know and like Rust
Well, this one's easy. I like Rust (citation: see the rest of this blog), and I hired developers who like Rust. We're already pretty productive in Rust. Would I choose Rust at a startup where nobody else knew Rust? Only if I was willing to spend a lot of time mentoring them. This didn't apply! We wanted to write Rust and we did, and it made us happy.
I have to stress: if nobody else on your team knows Rust, then the cost of teaching all your coworkers Rust will be high. It might take them a while to become productive in Rust, and you'll need to mentor and support them. Your own productivity will drop during this. Your default position should be to use a language the rest of the team knows, unless you really need Rust.
Luckily for me, my teammates already knew Rust, liked Rust, and wanted to become better Rust programmers, so this wasn't a concern.
2: Your service interoperates with services that are perf-critical
My team built Data Loss Prevention for Cloudflare. DLP basically runs "scans" on traffic going through some corporate network, to make sure nobody leaks private data, either maliciously or accidentally. For example, it could detect and block a hacker uploading millions of credit card numbers from your database to pastebin.org, or stop someone emailing Microsoft Word documents with certain Office labels to yahoo.com emails.
The service that actually scans HTTP traffic to prevent data loss is called, imaginatively, dlpscanner. From the start, we knew dlpscanner would be very performance-sensitive, because it's proxying a lot of HTTP requests, and we don't want users web browsing to be slowed down when they turn on DLP. So, we wrote that in Rust. We had two choices for the backend API: Rust or Go. The decision to use Rust was made by considering which would be more complicated: using Rust on the backend, or adding a second language to our codebase.
Software issues
When we started planning the backend API, we knew it would have to interoperate with dlpscanner. It would need to share a bunch of types, representing e.g. user configuration. The API server would serialize user configuration into JSON, and dlpscanner would deserialize that JSON whenever it needed to scan a request.
I would much prefer to have all that serialization and deserialization logic written in Rust, instead of having to define my models in two languages and check that language A can deserialize whatever language B was serializing. I know there's a whole host of tools like Captain Proto and Protocol Buffers to ease interop between different services, but including cross-language schemas and the generated code bindings is pretty annoying. Or I could just write some JSON transformations and carefully unit test it. But just writing normal Rust code seemed much simpler.
Basically, I like that I can share code between different parts of my system. Using Rust for both the perf-critical services and non-perf-sensitive services simplifies the overall codebase a lot.
People issues
It's hard to switch context between programming languages. Every time I go back to Go or JS, it takes some time to remind myself that "hey, you need to start field names with a capital letter to make them public" or "hey, you need to remember all the different gotchas for ==". Sticking to one language makes my life easier, and minimizes the number of new things I have to teach new teammates.
3: Serde
Serde deserves its own bulletpoint because I love it so damn much. My first few months working with Go I wrote lots of unit tests for JSON de/serialization because Go's comment-based approach meant that if I made a typo somewhere, the compiler couldn't catch it. For example, in the Go code below.
type response struct {
PageCount int `json:"pageCount"`
FirstNames []string `json:"firstNames"`
}
The comments are annotating each field with what its JSON de/serialized key should be. This is fine but it's pretty annoying if you have a lot of fields and need to manually convert them all to using snake_case instead of StandardGoFieldNameCase. And if you make a typo, oops, you're going to get a runtime error. Oh, and you'd better remember to annotate every field, because Go's JSON package can only deseriaize public fields (which start with a capital letter), and the other service probably expects fields to start with a lowercase letter (either snake_case or camelCase).
Instead, in Serde, I'd just write
#[serde(rename_all = "camelCase")]
struct Response {
page_count: i32,
first_names: Vec<String>,
}
This generates sensible code for de/serializing, no unit tests needed. Serde just comes with so many other attributes out of the box to help automate JSON tasks. And yeah, de/serializing JSON is a pretty core problem to any API backend, so you should try to ensure it's straightforward and doesn't require a ton of custom logic and unit tests.
Serde is also nice because you can start out only supporting JSON, but it's easy to add support for other serialization standards later on. If you wind up reusing these types in code which is really performance-sensitive (see above) then serde can handle a ton of other data formats which are faster to de/serialize.
I just ran into a ton of bugs in my JSON de/serialization in previous projects, but I've never had a single problem since I started using Serde. It's saved me a lot of time. If I had to write a new project that relied heavily on de/serializing data I'd try to use Rust just for that (or JS, if I knew the data was only going to be transported in JSON and that both ends could use JS).
4: Databases
Rust isn't amazing at databases but I do think it's very good at them. I really like using Diesel because it generates all your SQL queries for you, from a typed SQL schema that it generates from your SQL migrations. This solves a few problems:
- When you remove or rename a column in your SQL table, how do you check that all your existing queries were changed to understand the new schema?
- If you model your SQL tables/rows in your code, and you add/change/remove a column, how do you check that all your code types accurately model your SQL types? This is called the Dual Schema Problem. It's very annoying to keep your code schema (JS, Go, Rust, whatever) and your SQL schema in sync.
I don't like object-relational mappers in all languages, but Diesel is pretty nice because now when I update my SQL schema, Diesel will regenerate the appropriate Rust models, and almost all mismatches between my Rust and SQL code now become compiler errors that I can fix up.
Building a model of the SQL type system within the Rust type system is very impressive work. It also leads to really annoying problems, because the Diesel types are so complex. These include:
- Error messages over 60 lines long
- Error messages that make no damn sense ("this trait wasn't implemented", OK sure, but I thought it was, could you tell me why it wasn't? No? OK, guess I'll just cry a little)
- Difficult to factor out common code into shared function, because two similar-looking queries have wildly different types
But overall, if your application depends very heavily on the database for a lot of its functionality, I think it's worth making sure your database queries are properly typechecked. Database queries aren't some optional extra in an API backend, they're almost your entire codebase. So it's worth making sure they're correct.
Yeah you can just write all your SQL queries by hand and unit test them very carefully, but then you need to think really hard about your unit tests, keep them in sync with the production schema, and make sure you're not prone to SQL injection because you, I dunno, looped over an array of "filters" and mapped those into becoming SQL WHERE clauses. Diesel is a pain in the ass sometimes but overall I think it's been worth it.
Between Diesel and Serde, you can generate almost all the important code in your API (reading requests, doing database queries, and writing responses), leaving you more time to write business logic, ship features and focus on modelling your business domain. Oh, speaking of:
5: Better modelling of business domain
It's important that a backend API which stores user configuration can correctly model the real world in software. If the user is representing, say, their office layout in your software, then your type system should be able to model the office and not let the user push up invalid configuration.
And if possible, you want those invalid configurations to be detected at compile time instead of at runtime, to minimize the amount of tests and error-checking code you need. If a certain configuration can't occur in the real world -- e.g. no user's office can be located in two timezones -- then your software model should not be able to represent an office which has two timezones. This idea is called "make illegal states unrepresentable". There's a lot of articles written about it.
Rust has two features which really help you model your business domain accurately: enums and uncloneable types.
Enums
There's this really neat idea, called "sum types" or "tagged unions" or "algebraic data types" or "enums with associated values" depending on what language you're working in. I love sum types. I use them in my Haskell toy projects, in Swift when I was an iPhone dev, and in Rust at Cloudflare. They're just really good for modelling the business domain.
Enums let you say "This function either returns an error, or a Person struct. Not both. Not neither.
Exactly one of those two options." When I don't have enums, e.g. in Go, I need to carefully read
every function and check if the function that returns (Person, *err) can ever return neither value.
I like modelling the domain with enums. It's great to say "this user can start my software with either a TCP socket or a Unix socket", and know that the compiler will check that you never accidentally pass neither kind of socket, or a third kind of socket, or some other thing.
"Accurately modelling the business domain" is something I care about a lot in high-level APIs. Correctness matters. So, if I really need to make sure my software model accurately represents the real world, Rust gives me better tools to do this than Go.
Uncloneable types
A few years ago at Cloudflare, I needed to model a set of ten IP addresses. The idea was that the Cloudflare edge network had ten public IPs, and cloudflared was running on your server and connected to 4 of those 10 IPs for load-balancing purposes.
If one of those IPs was "unhealthy" and disconnected cloudflared, then cloudflared should avoid reusing it and instead use some IP it hadn't used before. A natural way to model this is that each IP has three possible states: in use, unused, and previously-used-but-now-unhealthy. Each of these IPs could be assigned to one of the four long-lived TCP connections.
This sounds like an easy problem to solve, but it was hard to model the idea that "each IP address can be assigned to at most one connection". I had to write a lot of unit tests to find edge cases where two different connections would each try to grab the same IP address. It was hard because in Go, every value can be copied. Trying to make sure there's only one copy of a particular string, like "104.19.237.120", requires a lot of programmer discipline. Go functions generally copy values around, or copy pointers to that value, so it's hard to ensure that only one goroutine is reading your value.
On the other hand, Rust makes it easy to ensure particular values are only being "used" in one
place. There can only be one &mut reference to a value at any time, so just make sure the functions
which "use" the value take a &mut to it. Alternatively, ensure your type doesn't impl Clone, and
make sure the functions which "use" it take full ownership of the value. The value will be moved
into the function upon move, and the function can "return" the value when it's done.
So, if I wanted to implement this system in Rust, I'd just keep a HashSet of my ten IP addresses,
and I'd make sure each connection took &mut to the IP it was using. I'd also make sure the IPs were
a newtype UncloneableIp(std::net::IpAddr) and that I did not derive Clone for that newtype.
This honestly doesn't come up very often in practice -- generally it's OK to copy bytes around in memory -- but when it does, it's pretty frustrating to try to audit every function and make sure none of them are copying a value or sharing references to it. You can probably simulate this with a RwLock (which, like the Rust borrow checker, only allows one thread to have a writeable reference to a value) but now if you get it wrong your code deadlocks, oops.
6: Reliability
Performance might not be a problem for your startup, but reliability probably is. Customers don't like paying for services that go offline. I know this from personal experience, I've been on both sides of that situation. I've maintained some really unreliable services for new products 😅
Avoiding footguns
One nice thing about my Rust backend services is that they basically never crash. There's no nil
dereferences that cause instant panics. Sure, there's Option, and you can always .unwrap() the
option which will cause a crash. But it's very easy to audit them in code review, because .unwrap()
screams "HEY PAY ATTENTION TO THIS, THIS COULD CRASH THE PROGRAM" in a way that just calling
".toString()" on a seemingly normal Javascript object does not. So it's pretty easy to notice in
code review. In practice Rust usually has better ways to deal with Options than unwrapping them, so
this has very rarely come up during my team's code reviews. 95% of the unwraps in our codebase are in
unit tests.
This reliability definitely comes with a little bit of developer overhead, like thinking about how
to properly pattern match all your Result and Option values. But for many domains this tradeoff
makes sense. Not all of them. I just happen to have worked on a lot of projects where going down was
Bad, and I'm happy to think more carefully if it avoids getting paged in the middle of the night.
Resource management
Rust doesn't tend to use much memory or leak resources (like TCP connections or file descriptors) because everything gets dropped and cleaned up when a function terminates. There are some exceptions, like it's possible to "leak tasks" like my Go servers leak goroutines. You gotta make sure to use appropriate timeouts everywhere. @ThePrimeagen works at Netflix and had an interesting twitter thread about using Rust for a "high level" service:
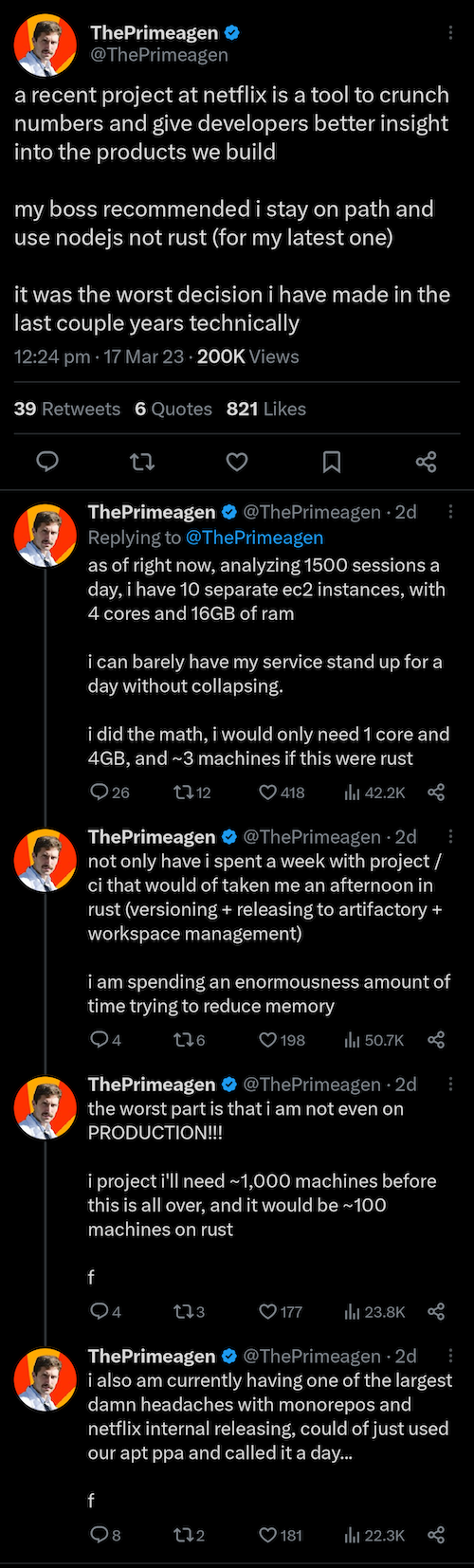
The lesson I took away from this is that, eventually, performance problems become reliability problems. If your service leaks memory for long enough, or ingests enough data, that performance bottleneck might bring down your service. This might not apply to your situation. But if you think there's a chance your traffic or usage could jump many orders of magnitude in one day -- for example, if a new big user signs up who's multiple OOMs larger than your current customers -- maybe it's worth thinking about.
Conclusion
I think Rust can do an admirable job as a high-level language. Especially when you're working on web services, Rust can save you time via libraries like serde and Diesel. The type system makes modelling your business domain much easier. And your service probably won't go down very often.
Using Rust for your web services might still be a really bad idea. Especially if your team doesn't have much Rust experience. The Rust difficulty curve is much lower than it used to be, but it's still high enough that you should default to using a language your team already knows.
At Cloudflare, most of our perf-sensitive services use Rust, but most of our perf-relaxed services (like API backends) use Go. My team used to use Go for backends and slowly migrated over to Rust for reasons in this article. That tradeoff doesn't make sense for every team, mostly due to the cost of learning Rust and rewriting core business libraries in Rust (e.g. your company might already have key libraries that most projects integrate for e.g. modelling user configuration or authenticating with an API gateway). But an increasing number of teams are considering using Rust for their backend.
Again, my general heuristic is to use whatever language your team already knows that will get the job done. But if your team does already know Rust, then it's definitely worth considering it for "high-level" projects.