Investigating crazy compile times
- Background: Generating API clients from OpenAPI specs
- Finding the slow compile time
- OK, I'll bite: why was it so slow to compile?
- Fixing it
- Takeaways
I hate long compiles. I spend hours of my time trying to reduce minutes of compile-time. I recently noticed that the KittyCAD Rust API client was taking an incredibly long time to compile in release mode. Weirdly, the compile time in debug mode was totally fine. I managed to shrink the release compile-times from 33 minutes to 1.5 minutes. Here's how.
Background: Generating API clients from OpenAPI specs
If you run a public API that you want people to use, you'd better document its schema. But keeping the API implementation in sync with the schema is difficult. Every time you make a change to your API, you've got to ensure you update its schema. This was a big problem for me at Cloudflare, where I was constantly forgetting to change my API schema when I changed the API itself.
At KittyCAD we solve this problem comprehensively. KittyCAD's API server uses dropshot to generate an API schema (in OpenAPI format) from the actual server code. This ensures the API schema we publish is always up to date. No more worrying about keeping the API schema and implementation in sync. Dropshot takes care of that for us. Dropshot was invented at Oxide Computer Company, which our CEO, Jess Frazelle, cofounded. When she started KittyCAD she brought a lot of good practices with her, including Dropshot. I love using it!
We also generate API clients from this OpenAPI schema. We generate Python, TypeScript, Go and Rust clients, but I've only worked on the Rust generator, which outputs the kittycad crate. We wrote a program called openapitor to generate high-quality Rust crates. There are existing "OpenAPI to Rust client" generators, but ours also generates documentation and examples, an improvement over the existing generators.
When we change the API, here's what happens:
- I open a PR to change an API endpoint
- A unit test checks that the OpenAPI schema was updated, and will be accurate once the PR merges
- I merge the PR
- Merging the PR triggers a GitHub action
- The action checks out kittycad.rs, copies the updated OpenAPI schema over the previous schema, regenerates the Rust client, and opens a PR with the new code.
- I review the PR and merge it.
Finding the slow compile time
I noticed that compiling the KittyCAD CLI was taking a really long time, so I ran
cd cli
cargo clean && cargo build --release --timings
to generate a nice diagram showing why it was taking so long. The culprit was clearly the KittyCAD Rust API client. The cargo --timings diagram can't show me why that crate takes so long to build, though. I knew it didn't always take that long, so something must have changed.
We use GitHub Actions a lot at KittyCAD, so I looked back through the action runs for publishing our CLI, and found the exact commit where our compile-times suddenly got crazy long.
I could read through that commit to figure out which version of KittyCAD's Rust client had caused the compile times to blow up. I traced it to this commit. I read through the commit, trying to figure out which part was making compiles so slow.
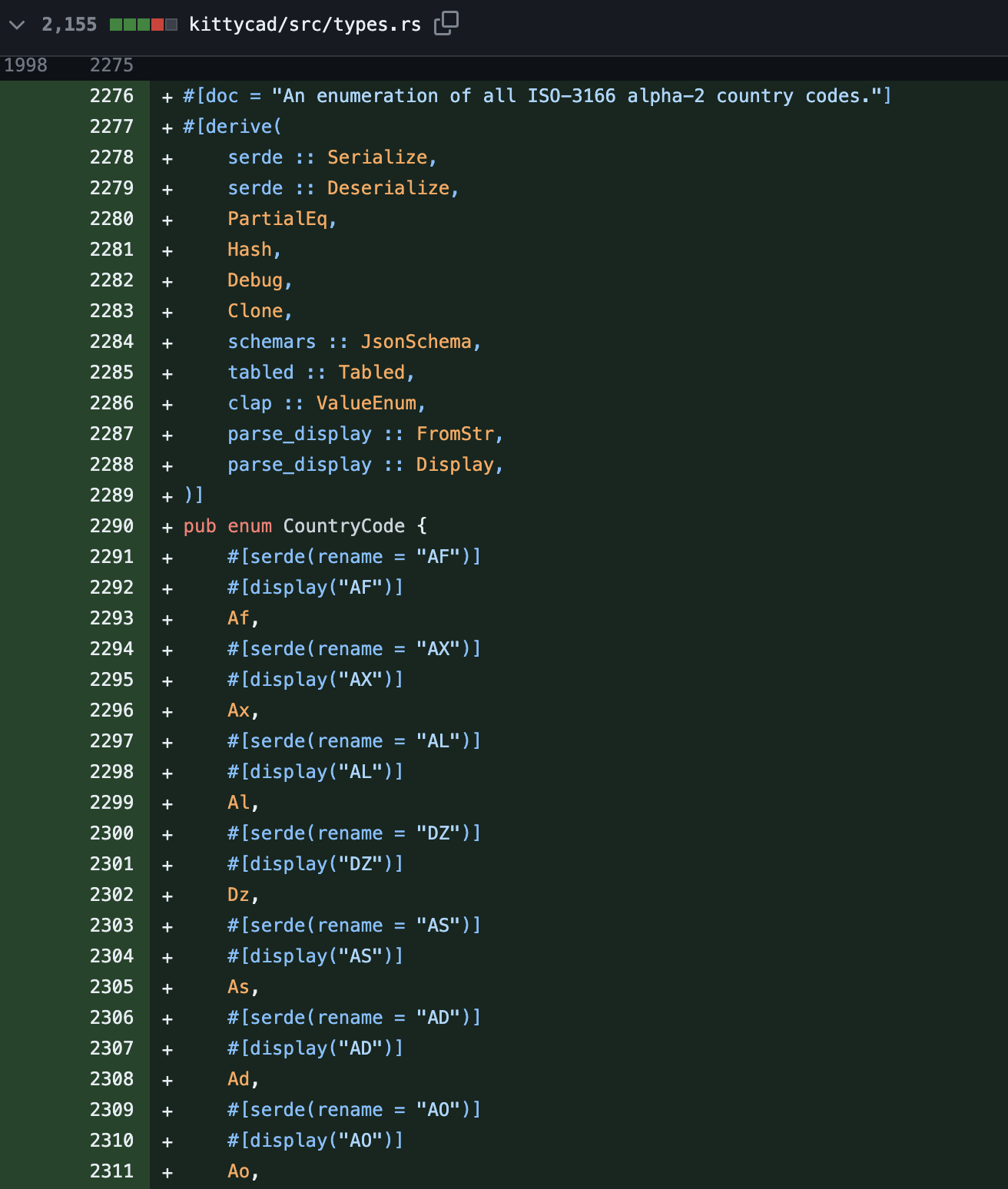
Oh, huh, that PR added a Rust enum with one variant for every country in the world. And a second enum for every currency code. Yeah that seems like it might be the cause. It's definitely suspicious. As an experiment, I deleted half the enum variants, erasing half the countries of the world like Thanos. Rerunning the build confirmed that compile-times dropped dramatically. Further experimentation with the highly scientific methodology of "comment out more and more code" confirmed that the compile-time was quadratic in the number of countries.
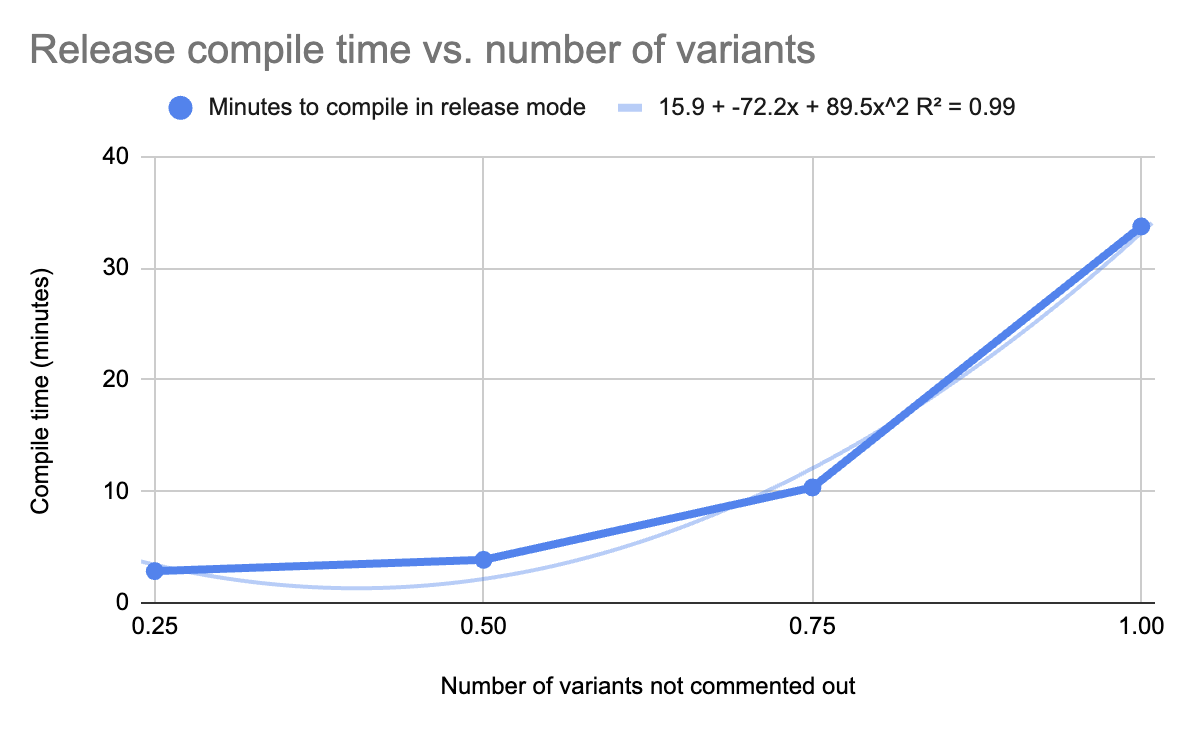
But I was still pretty confused about why this enum was so slow to compile.
OK, I'll bite: why was it so slow to compile?
I'm so glad you asked. I read through "Why is my Rust build so slow?" to learn how to dive deeper into Rust compile-times. I recommend reading it, it's a great article. I tried each tool listed there, and I couldn't really interpret what I was seeing. It just seemed like Cargo was spending a lot of time compiling a lot of code. If I had kept reading, I would have found the solution to my problem in the very last paragraph before the conclusion. But I was distracted from reading because I was simultaneously talking with Jyn Nelson and Noah Kennedy. I used to work with them in the Cloudflare Austin office, we all love Rust, and they're smart fun people I like bouncing ideas off. Jyn has worked on the Rust compiler and Noah is a Tokio maintainer, so I thought they'd have good suggestions.
Jyn suggested using cargo llvm-lines to see which Rust functions expanded into the most lines of LLVM. When you compile Rust, it goes through several stages -- it first compiles your source code to "high level intermediate representation" or HIR (see this EuroRust talk by Arpad Borsos for more about HIR, I found it really interesting). HIR gets compiled to mid-level intermediate representation (MIR) and then to LLVM. LLVM is like a very high-level machine code that many programming languages compile to. Then the LLVM tooling compiles that LLVM into machine code for a particular target. When you run cargo llvm-lines it shows you how many LLVM lines each Rust function actually gets compiled into.
My theory was that deriving serde's Serialize and Deserialize traits was causing a ton of code for each variant, and there were 300 variants, so it'd generate a lot of LLVM. I was completely wrong!
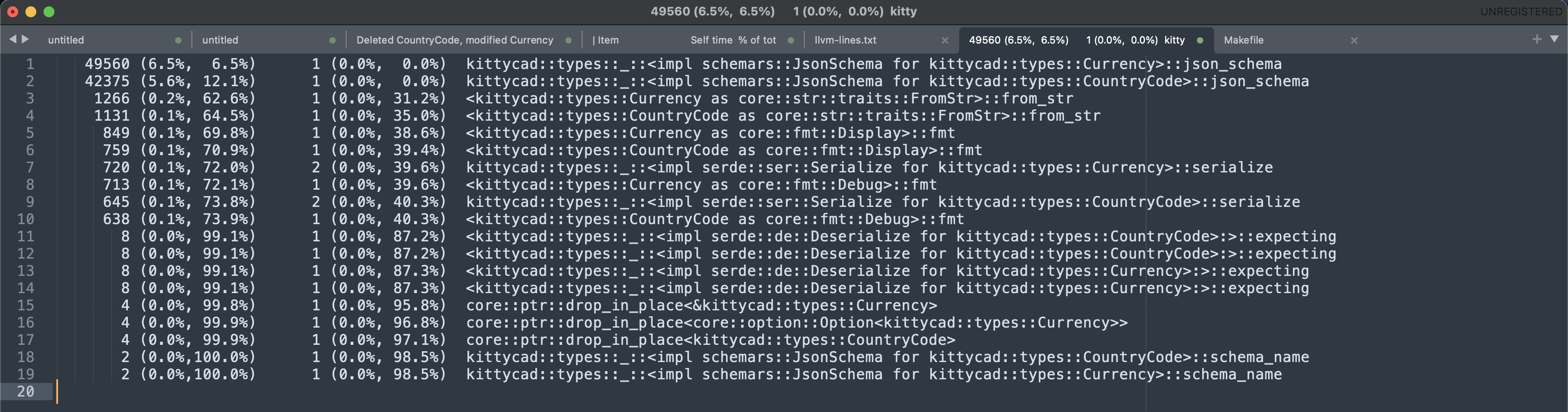
Yep, deriving a JsonSchema impl for the CountryCode and Currency enums was compiling down to an absurd amount of LLVM. That trait is from the schemars library. We use it to generate OpenAPI schemas for various Rust types. I visualized the cargo llvm-lines output:
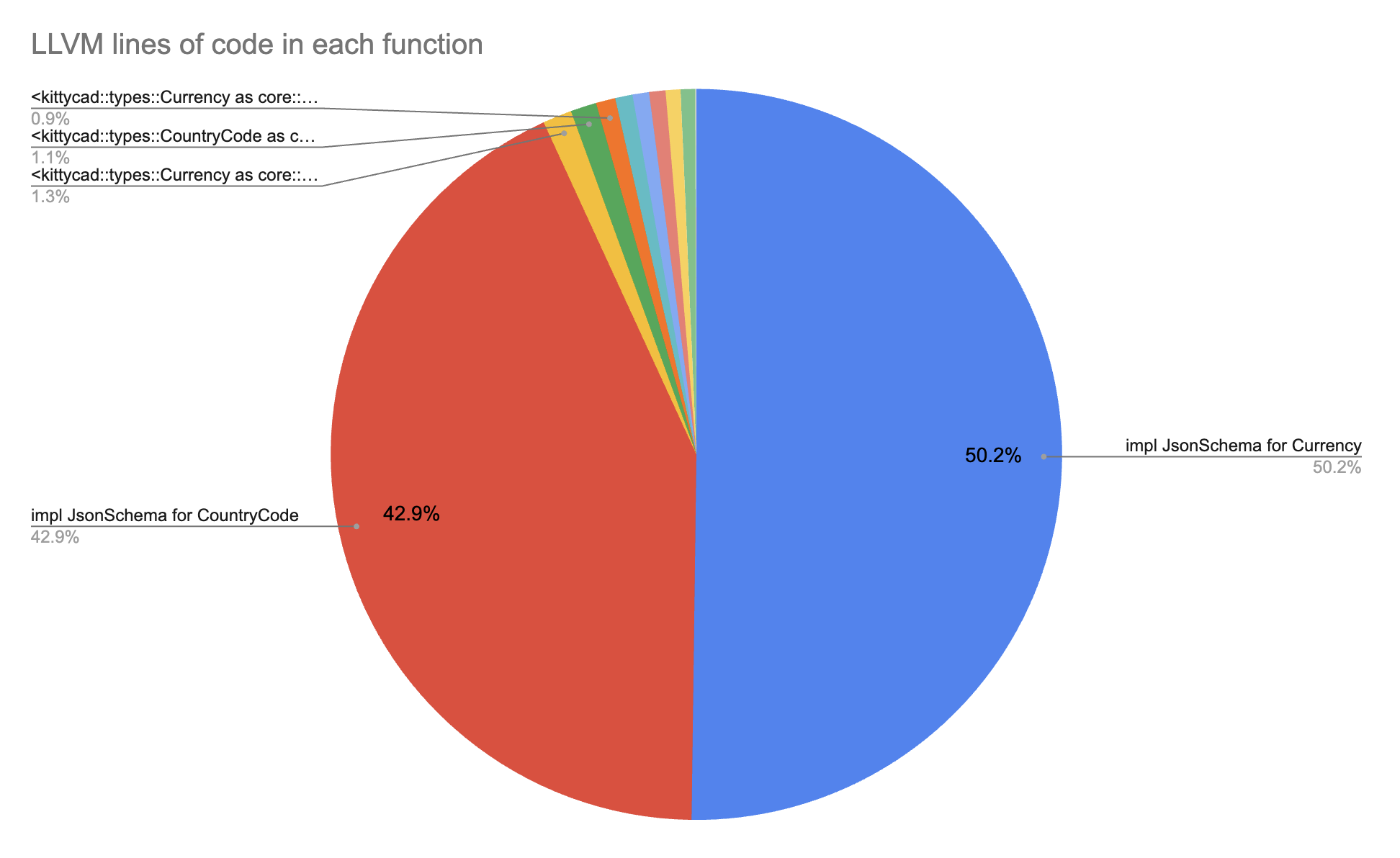
Yep, that's the problem. Jyn said that
in general LLVM is quadratic or worse on large functions so this isn't too terribly surprising to me
That fits perfectly with what I observed. Tiny enums are fine to compile, but as they get longer, the quadratic time that LLVM spends optimizing becomes worse and worse.
Fixing it
The immediate fix was clear. Our OpenAPI schema shouldn't contain a list of every single valid country code. Instead, it should just accept a string, and the server should send a HTTP 400 Invalid Request if the user didn't input a valid two-letter country code. This is, in my opinion, a shittier user experience, because if you're trying to program with KittyCAD's API client, you now need to find a list of valid country codes instead of using one built into the API client. But it's worth it to make our API client compile in 1.5 minutes instead of 40.
Ultimately, deriving JsonSchema should not take this long. Sometimes you genuinely need a lot of variants on an enum. So I filed an issue on the crate describing the problem and providing an example project which demonstrated the problem. Reproducing the problem was actually really hard. My reproduction example was only generating a tiny amount of LLVM lines! Why couldn't I induce the behaviour?
Well, it turns out the Rust compiler was optimizing the enum out, because this was a library, not a binary. The enum wasn't actually used. I converted the project to be a binary and actually use the enum, then it worked.
Jyn helped me view the MIR this code generates, and it's mostly doing a lot of dropping fields. A few weeks later, the crate's maintainer found a tiny change which decreased the MIR output (and therefore the LLVM output) around 30%. This sped up compiling KittyCAD's Rust client by 35%, a huge win!
That improvement was a super promising start, and we're both hopeful that further improvements are possible. I don't really understand the code enough to dive in yet, but maybe some day I'll take a closer look.
Update
In version 0.8.19, schemars has made massive progress around this issue! Release compile time has been halved again! Another huge win. The relevant PR has more details.
Takeaways
- Use
cargo build --timingsto visualize which crates are slow to compile - Use
cargo llvm-linesto check that a crate is generating a reasonable amount of LLVM. If you're generating tens of thousands of lines of LLVM, you're probably doing something silly with macros or build scripts. - LLVM optimization takes quadratic time in function length. It might be faster to compile many small functions rather than one big function.
- Read "Why is my Rust build so slow?" for more ways to investigate build times.
Thanks to Jyn and Noah for helping me debug this one, and to Graham Esau for the schemars crate and his help fixing its compile times.